深度学习中静态图动态图
相关知识
目前神经网络框架分为静态图框架和动态图框架,PyTorch 和 TensorFlow、Caffe 等框架最大的区别就是他们拥有不同的计算图表现形式。 TensorFlow 使用静态图,这意味着我们先定义计算图,然后不断使用它,而在 PyTorch 中,每次都会重新构建一个新的计算图。通过这次课程,我们会了解静态图和动态图之间的优缺点。
对于使用者来说,两种形式的计算图有着非常大的区别,同时静态图和动态图都有他们各自的优点,比如动态图比较方便debug,使用者能够用任何他们喜欢的方式进行debug,同时非常直观,而静态图是通过先定义后运行的方式,之后再次运行的时候就不再需要重新构建计算图,所以速度会比动态图更快。
动态图:在计算的时候,就会把计算过程动态图存储起来。每次前向过程都会重新建立一个新图。
静态图:静态图需要预先定义好运算规则流程,然后把运算流程存储下来。
两者的区别用一句话概括就是:
- 动态图:运算与搭建同时进行;灵活,易调节。
- 静态图:先搭建图,后运算;高效,不灵活。

Pytorch中的动态图
动态图的初步推导:
- 计算图是用来描述运算的有向无环图
- 计算图有两个主要元素:结点(Node)和边(Edge);
- 结点表示数据 ,如向量、矩阵、张量;
- 边表示运算 ,如加减乘除卷积等;
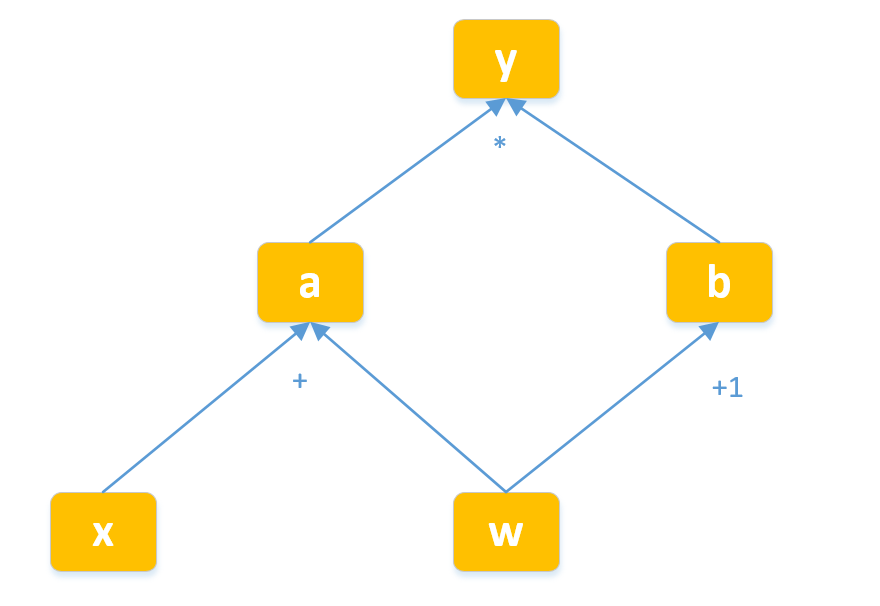
上图是用计算图表示:
其中, a=x+w,b=w+1,y=a∗b,(a和b是中间变量),Pytorch在计算的时候,就会把计算过程用上面那样的动态图存储起来。现在我们计算一下y关于w的梯度:∂y/∂w = ∂y/∂a * ∂a/∂w + ∂y/∂b * ∂b/∂w = b * 1 + a * 1 = b + a = x + w + w + 1 = 2w + x + 1。
用Pytorch的代码来实现这个过程:
1 | |
图中的叶子节点,是w和x,是整个计算图的根基。之所以用叶子节点的概念,是为了减少内存,在反向传播结束之后,非叶子节点的梯度会被释放掉,我们依然用上面的例子解释:
1 | |
可以看到只有x和w是叶子节点,然后反向传播计算完梯度后(.backward()之后),只有叶子节点的梯度保存下来了。
当然也可以通过.retain_grad()来保留非任意节点的梯度值:
1 | |
torch.tensor有一个属性grad_fn,grad_fn的作用是记录创建该张量时所用的函数,这个属性反向传播的时候会用到。例如在上面的例子中,y.grad_fn=MulBackward0,表示y是通过乘法得到的。所以求导的时候就是用乘法的求导法则。同样的,a.grad=AddBackward0表示a是通过加法得到的,使用加法的求导法则。
1 | |
结尾
本文章摘抄于头歌教学平台中深度学习课程中静态图动态图的设计一节。
觉得写的很好,故保留下来用于复习。