AlexNet实现
前言
这是在两年前接触的第一个CNN,当时也是糊里糊涂的理解。去年读过了AlexNet源论文,第一次好好推导了一遍,过后也复现了一次,不过没有好好保存,后面重装电脑无意中删掉了。
刚好要给大一学弟做培训,就打算来再做做AlexNet,也当是给之前的记录补上了。
Alex 结构
AlexNet结构十分简单,仅用到了卷积、池化、全连接。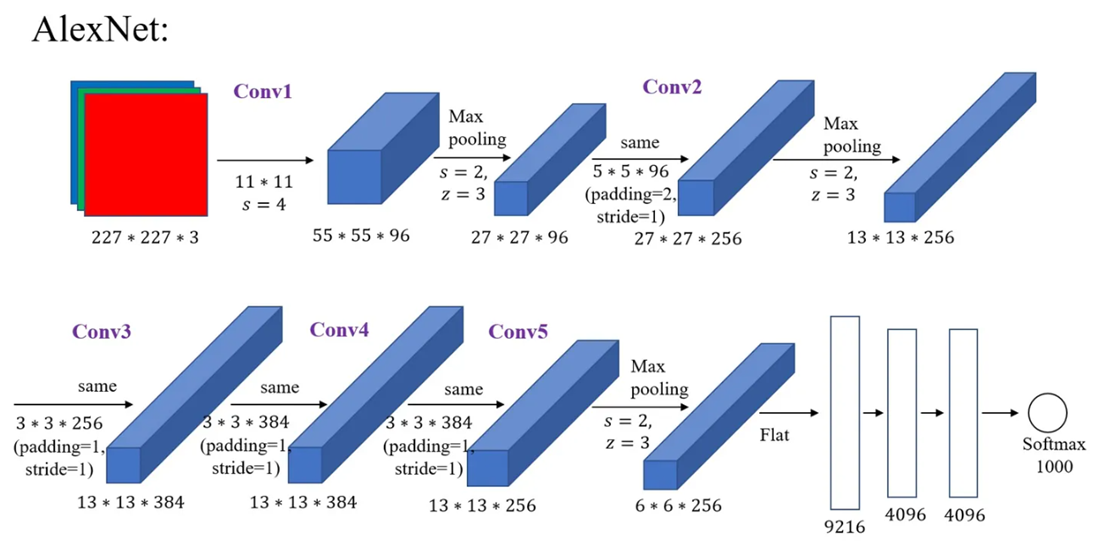
卷积对尺寸的变化是W = (W - K + 2P) / S + 1
池化对尺寸的变化是H = (H + K) / S + 1
第一要注意原文中使用双GPU训练,故自己跑的话图像深度缩小一半
下图很好说明了参数和尺寸的变化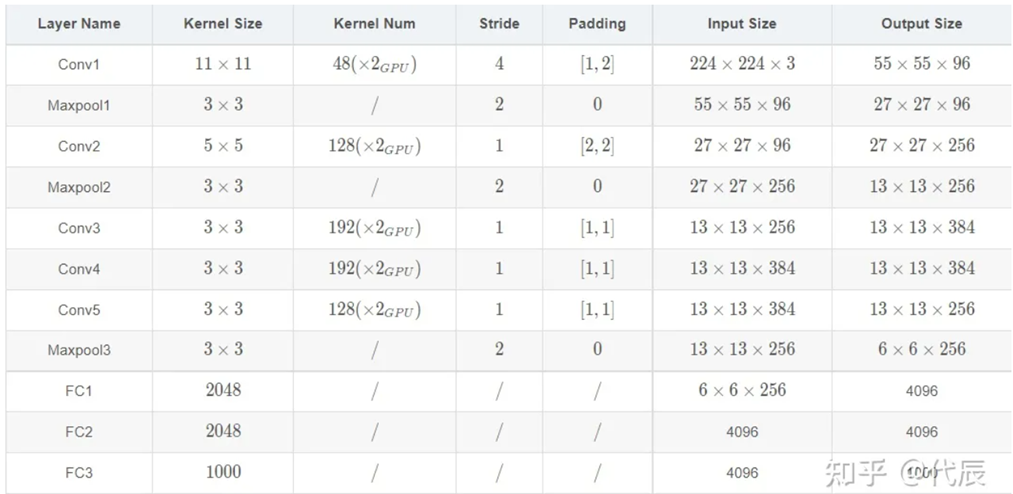
第二的注意的点是原文中尺寸是227,但实际操作时应为224才是正确的
接下来就可以开始准备搭建了
实现AlexNet
Create The Model
首先导入pytorch需要的库
1 | |
summary可选,用来输出网络
接下来开始创建AlexNet,开始根据上面的参数设置
1 | |
这个类中创建两个函数
- 在
__init__中定义了2个属性,分别是features、classifier,用于卷积和全连接,在里面使用了nn.Sequential创建。 - 在forward中连接了网络结构
继承了nn.Module类:
1 | |
把矩阵展长成一维的:
1 | |
更具体一些相信没什么问题了,这里不过多阐述。
Prepare The Dataset
包含加载数据和预处理,在dog_cat文件夹下存放有train、val文件夹,里面分别有dog、cat文件夹用于存放猫和狗图片。这里给出一个别人的百度网盘的连接可以用于下载百度网盘猫狗数据集下载链接, 密码:485q,来自csdn博客
下面是代码,这个写法比较整洁,当然也可以分开创建,在数据处理中并没有过多的处理,如果想要有其他的变化在transforms.Compose中加入就可以了。
1 | |
这样写有几个好处:
- 因为数据集的格式我们不用自定义data_loader类,当然如果不嫌麻烦也可以自己写一个
- 代码在使用时十分的整洁,在加载时需要指定
dataloaders[phase]中的phase
当然如果不是很清楚其中的变量打印出来看看就明白很多了。
Start Train
在这里只保存了最后一次训练的结果,如果想更完善一些可以对比每一次epoch的精度来选择性的保存结果。
1 | |
在这段代码中可能需要解释的主要是:
1 | |
上述代码是用于控制是否计算和存储梯度。这个语句是一个上下文管理器,它会根据参数 mode 来启用或禁用梯度计算。
这种做法常见于机器学习模型的训练和验证阶段。在训练阶段,我们需要计算梯度以更新模型的参数;而在验证阶段,我们通常不需要计算梯度,因此可以禁用梯度计算以节省内存。
其他的地方无非就是计算损失criterion(outputs, labels)、计算梯度loss.backward()、更新参数optimizer.step()。记得在开始的时候清空梯度optimizer.zero_grad()。
Start Predict
经过刚才的步骤会得到一个model.pth这个文件,接下来我们将预测单个模型,下述代码的前部分是预测,后半部分是可视化,有关预测和可视化的地方也没什么好说了,看一看就能明白。
1 | |
最后的效果: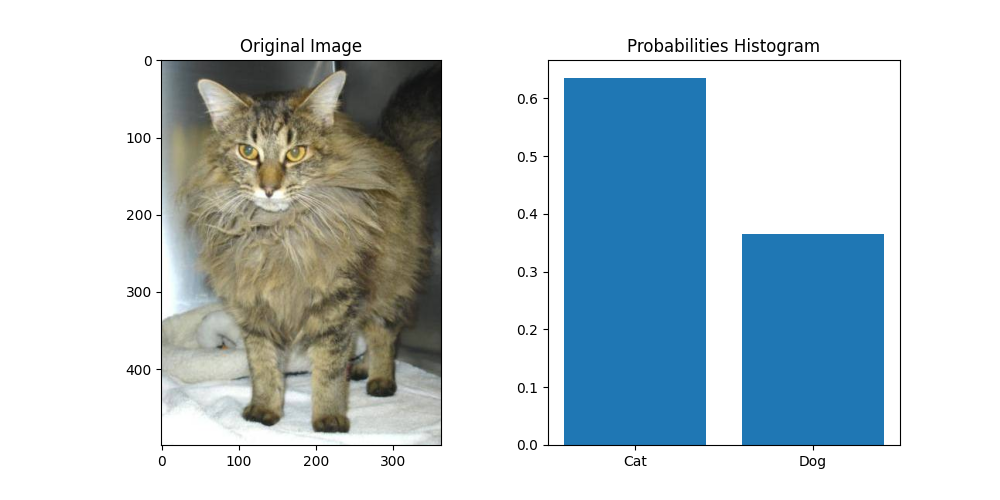
这里训练的比较少,效果也只能说将就,至少看起来还是有点像样子的。
总结
按照上面的步骤不出意外应该是没有问题的,很适合很久没看或者是新手用来复习和学习,也算是给我之前的学习做一个小总结。
希望能帮助到你,有问题可以联系邮箱:jiahhhao@outlook.com,或者在关于中用其他的联系方式,我会尽快回复你,当然如果问题网上能查到最好自己解决~